| Breakdown | Group | # Tasks | GPT-5.3-Codex | Gemini-3.1-Pro | Grok-4.20 | GPT-5.4-Mini |
|---|---|---|---|---|---|---|
| Overall | All tasks | 51 | 51.0% | 27.5% | 11.8% | 7.8% |
| Category | AI/ML | 25 | 52.0% | 16.0% | 8.0% | 0.0% |
| Sci. Computing | 7 | 42.9% | 57.1% | 14.3% | 0.0% | |
| Systems | 19 | 52.6% | 31.6% | 15.8% | 21.1% |
LLM agents have made rapid progress on software engineering and ML research tasks, but these advances often assume access to a working runnable environment. For research artifacts released alongside published papers, setting up such an environment from a fresh machine remains a major bottleneck. Existing environment-setup benchmarks do not cover the full scope of research-artifact deployment, which involves multi-language toolchains, system-level dependencies beyond containers (e.g., GPU/CUDA and kernel configurations), and legacy artifact compatibility.
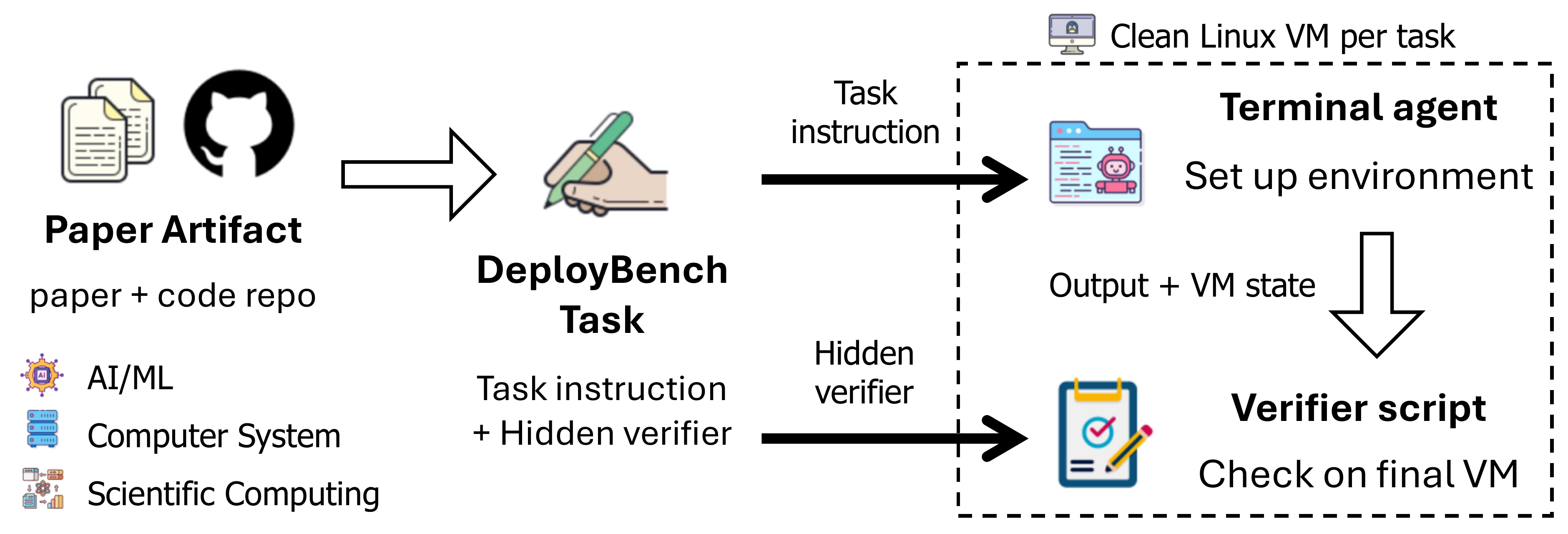
We introduce DeployBench, a multi-domain benchmark of 51 research-artifact deployment tasks drawn from top-tier venues published between 2008 and 2025, spanning AI/ML (25), computer systems (19), and scientific computing (7). The tasks cover 11 programming-language ecosystems and include 22 GPU-dependent workloads, 5 tasks that compile and boot custom Linux kernels inside a QEMU virtual machine, and 10 legacy artifacts (2011–2018) that require compatibility repair against modern toolchains. By setup difficulty, the set splits into 12 easy, 20 medium, and 19 hard tasks.
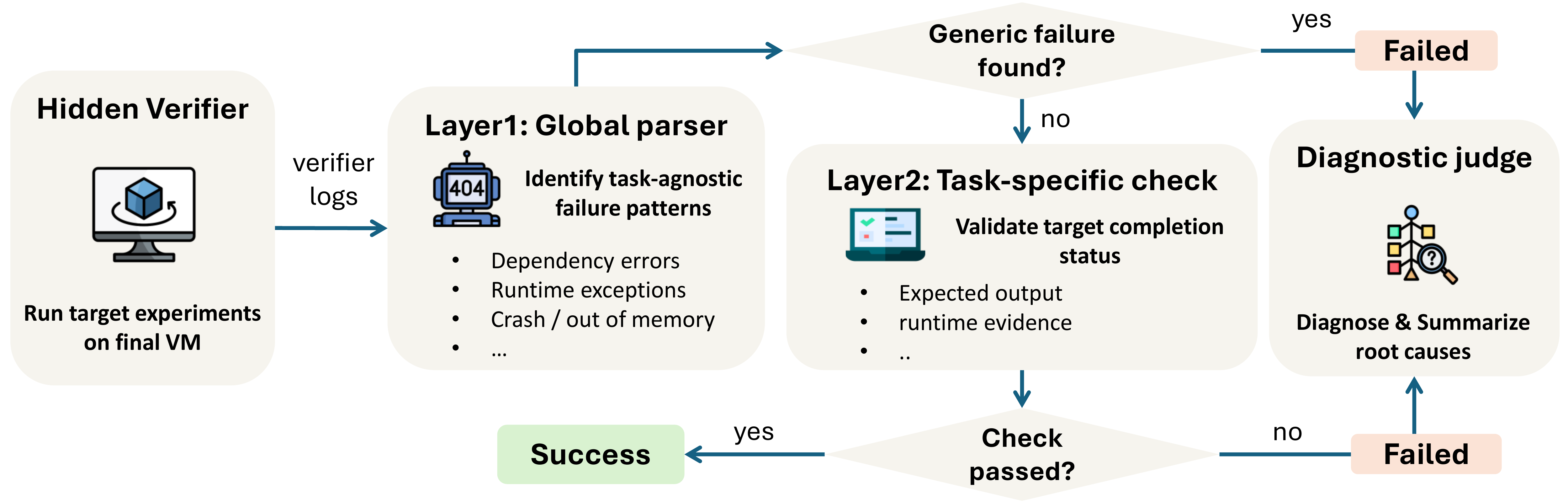
Every task is given the paper, its code repository, and a fresh cloud VM with no pre-installed drivers; Docker is disallowed so that success reflects native dependency resolution. Each task is verified by a hidden pipeline that executes the paper's designated experiment and checks its outputs, and we confirm that all 51 tasks can be deployed by running the reference setup scripts. DeployBench highlights the gap between current agents and autonomous deployment, and offers a realistic testbed for scientific research agents.